Updated on September 29, 2023.
How to Use Data Classification for a SOX-Compliant ALM Process in Salesforce
Robust data classification is a fundamental element of a data governance policy. It’s also critical to ensuring SOX-compliant Salesforce application lifecycle management (ALM). By classifying financial data correctly and protecting its integrity, you can avoid violating SOX regulations.
Let’s examine this topic more closely by explaining the role of data classification in a SOX-compliant Salesforce ALM process. We discuss the risks of using financial data during testing and how to avoid them. We also highlight the potential impact of Salesforce changes on financial data.
Robust Data Classification Protects Against Noncompliance
When you manage your Salesforce data and deployments effectively, they result in the changes you want. However, when your data classification isn’t properly managed, it can potentially expose sensitive financial information. And that could result in a violation of SOX regulations.
Incorrect Data Classification in Practice

In practice, if financially-impactful data isn’t identified as sensitive, it could accidentally be exposed to unauthorized users during the release process.
For example, let’s say a developer is testing a new feature with sensitive financial data. However, they don’t know they should mask or obfuscate that data. In a situation like this, they could unintentionally expose it to unauthorized individuals. Someone could simply walk by their laptop and see the data on their screen. Similarly, if the developer’s laptop is compromised, the data could be stolen, which places the company at risk.
At the same time, consider what would happen in this scenario: You’re working on a change that will impact financial data. However, you’re not aware that the data in question is financial data. When an error slips into the code, you don’t see it, and neither does anyone else on the team—so you promote the change to your production instance. This could easily result in a glitch that snowballs from a minor bug into a huge issue that impacts the integrity of your financial data.
These scenarios are both realistic examples of how incorrect data classification can lead to SOX violations.
Consequences of Incorrect Data Classification in ALM
If you don’t consider data classification during the Salesforce application lifecycle management process, the fallout can be serious. And if your company is public, it could face severe consequences stemming from a violation of SOX regulations.
Noncompliance with the Sarbanes-Oxley Act of 2002 (SOX) can put your CEO and CFO at risk of fines and imprisonment. Your organization can also be subject to fines. Other potential consequences include delisting from the stock exchange and civil penalties.
However, it doesn’t stop there. If an audit calls the integrity of your financial reporting into question, you’ll almost certainly lose the trust of your customers and investors. And once that trust is lost, it can be incredibly challenging to win it back.
The Role of Data Classification in SOX-Compliant ALM
In the Salesforce change management process, you might have to use sensitive data for testing to ensure a change provides the functionality you want. When situations like this occur, you need to leverage data classification to prevent financial data from being exposed.
Let’s take a closer look.
The Risk of Using Financially-Impacting Data for Testing
In the release process, you generally won’t want to use any sensitive data for testing. However, sometimes you need to use it to test how a specific type of data responds to a change. And when it comes to financial data, you need to make sure it’s adequately protected during the testing stage.
Of course, you can always use dummy data. However, if the data isn’t as close to the real data in your production environment as possible, it will impact the quality of your changes. So you need a way to provide your developers with test data you replicate from production without giving them access to sensitive information.
How to Protect Sensitive Data During Testing
Fortunately, there are ways to protect the integrity of your financial data during testing. They include data masking, data redaction, and data obfuscation, as well as using 1-click scratch org automation.
Data Masking, Data Redaction, and Data Obfuscation
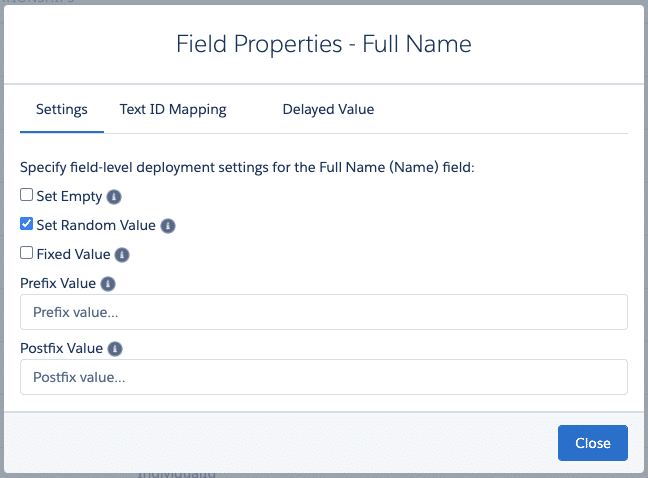
To protect sensitive data during the testing stage, use data masking, data redaction, or data obfuscation when you populate a sandbox with test data. In other words, when preparing the test environment, you select the financial data but mask, adjust, or scramble it so the developer can’t read the real information.
For example, when you set up a test environment, you could mask the dollar amounts of closed deals so your developer can’t see that information. You could also redact the data and replace numbers with asterisks or a dummy number like 0. Or you could obfuscate the data by scrambling the numbers completely.
One of the easiest, fastest, and most secure ways to do this is with Prodly’s sandbox seeding feature. This lets you instantly replicate data from production into up to five environments in one go—while masking or redacting the data with a single click.
Another benefit of Prodly is that it masks or obfuscates the data before it goes into the development environment. That means the team member preparing the environment can be authorized to see it, but the developer who’ll be working in the org will never see it. This adds yet another layer of security to your data protection.
1-Click Scratch Org Automation
You can also spin up a scratch org with precisely the right metadata and data for your purposes. Prodly provides a 1-click scratch org feature that lets you do this effortlessly. Just like with sandbox seeding, you can choose which data to replicate from production into your environment. And you can protect sensitive financial data with data masking or data redaction simply by selecting the option you want.
Data Classification Is a Continuous Learning Cycle
As we’ve seen, data classification plays a crucial role in Salesforce ALM—particularly when it comes to ensuring SOX compliance. When you effectively and consistently classify data and cautiously manage changes, you can ensure a secure and compliant ALM process. After all, in today’s data-driven business world, ensuring data integrity isn’t just a goal—it’s a necessity.
FAQs
What is data classification?
Data classification is a critical aspect of data governance that focuses on categorizing data based on its sensitivity, as well as its significance to the organization. You use data classification to determine who can access which data and what level of security is allocated to each data type.
Data classification simplifies data management by delineating security levels and access controls. This leads to more efficient use of data, as well as enhanced data security. When it comes to SOX compliance, robust data classification is key to ensuring financially impactful data is managed and used appropriately. Learn more about data classification in Salesforce.
Why do you need data classification?
The process of classifying data serves multiple purposes:
- It simplifies data management by clearly prescribing access controls.
- It assigns the right security levels.
- It ensures that each piece of data is handled appropriately.
Data forms the backbone of your organization, so understanding its nuances and significance is more important than ever before. At its core, data classification is all about bringing order and security to data by assigning each piece of data a sensitivity level that reflects its importance to the company.
Why is data classification important for a SOX-compliant ALM process?
In the context of SOX compliance for ALM, implementing a robust data classification process is essential. The Sarbanes-Oxley Act—or SOX—emphasizes the importance of transparency and accountability for publicly-traded companies in their financial reporting.
To adhere to regulations, it’s crucial to be able to distinguish clearly and quickly between financial and non-financial data. Data classification is instrumental in this respect. It promotes the clear separation of different types of data. That in turn helps you create a robust, SOX-compliant data governance framework that helps prevent noncompliance in the ALM process.